|
I am an AI researcher at Meta, where I develop real-time diffusion models for personalized AI assistants. Prior to joining Meta, I was a Member of Technical Staff at WaveForms AI, focusing on multimodal diffusion models. Earlier, as a researcher at Amazon, I was a core contributor to the Nova foundational models for multimodal generation. I earned my Ph.D. in Neuroscience and Artificial Intelligence from the Neuroscience and Cognitive Science (NACS) program at the University of Maryland, College Park (UMD). My PhD research focused on video understanding and 3D computer vision for autonomous vehicles. Email / GitHub / Google Scholar / LinkedIn / X |

|
| Publications · Experiences · Teaching · Volunteering |
|
My selected publications are listed here. The complete list of publications can be seen from my Google Scholar page. |
 
|
Amazon Artificial General Intelligence, 2024 technical report / video Core contributor to Amazon Nova Reel, an advanced video generation model within the Amazon Nova foundation suite, designed to produce high-quality, customizable outputs with fine-grained motion control. |

|
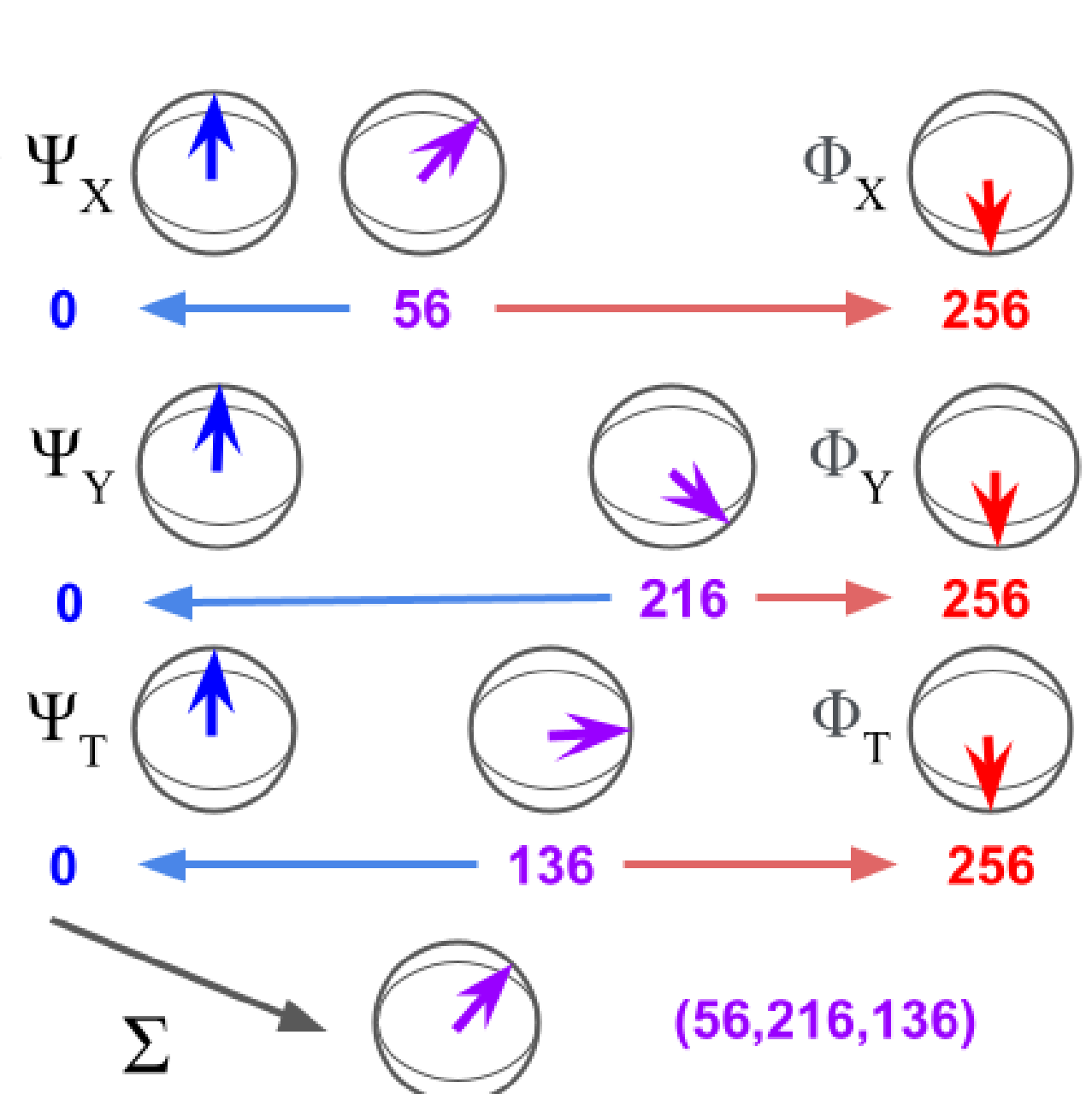
Chethan Parameshwara*, Alessandro Achille*, Matthew Trager, Xiaolong Li, Jiawei Mo, Ashwin Swaminathan, CJ Taylor, Dheera Venkatraman, Xiaohan Fei*, Stefano Soatto* (* equal contribution) arXiv, 2023 We describe a first step towards learning general-purpose visual representations of physical scenes using only image prediction as a training criterion. |
|
Neal Anwar, Chethan Parameshwara, Cornelia Fermüller, Yiannis Aloimonos CISS, 2023 project page / arXiv We present a novel bipolar HD encoding mechanism designed for encoding spatio-temporal data of an asynchronous event camera. |
 
|
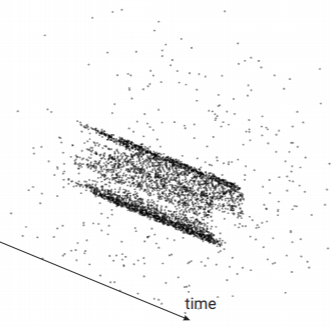
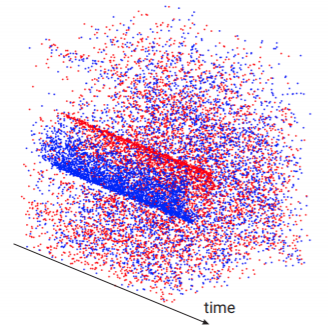
Chethan Parameshwara, Gokul Hari, Cornelia Fermüller, Nitin J. Sanket, Yiannis Aloimonos CVPR, 2022 project page / arXiv / video We propose a novel differentiable programming technique for camera pose estimation in autonomous driving and flying scenarios. |
|
Chethan Parameshwara*, Simin Li*, Cornelia Fermüller, Nitin J. Sanket, Matthew S. Evanusa, Yiannis Aloimonos (* equal contribution) IROS, 2021 project page / code / arXiv / video We propose a bio-inspired neural network for the motion detection problem using an asynchronous event camera. |
 
|
Chahat Deep Singh*, Nitin J. Sanket*, Chethan Parameshwara, Cornelia Fermüller, Yiannis Aloimonos (* equal contribution) IROS, 2021 project page / arXiv / video We present a novel approach to segment never-seen objects by physically interacting with them and observing them from different views. |
 
|
Chethan Parameshwara, Nitin J. Sanket, Chahat Deep Singh, Cornelia Fermüller, Yiannis Aloimonos ICRA, 2021 project page / code / arXiv / video We propose a hybrid solution to multi-object motion segmentation using a combination of model-based and deep learning approaches with minimal prior knowledge. |
 
|
Nitin J. Sanket, Chahat Deep Singh, Chethan Parameshwara, Cornelia Fermüller, Guido de Croon, Yiannis Aloimonos RSS, 2021 project page / code / arXiv / video We present a deep learning-based solution for detecting propellers (to detect drones) for mid-air landing and following. |
 
|
Chethan Parameshwara*, Nitin J. Sanket*, Chahat Deep Singh, Ashwin V. Kuruttukulam, Cornelia Fermüller, Davide Scaramuzza, Yiannis Aloimonos (* equal contribution) ICRA, 2020 project page / code / arXiv / video We present the first deep learning based solution for dodging multiple dynamic obstacles on a quadrotor with a single event camera and onboard computation. |


|
Anton Mitrokhin, Cornelia Fermüller, Chethan Parameshwara, Yiannis Aloimonos IROS, 2018 project page / code / arXiv / video We present a novel motion compensation approach for moving object tracking with an asynchronous event camera. |
|
|
|
Research on real-time diffusion models for personalized AI assistants. |
|
Research on real-time multimodal diffusion models for audio-video generation. |
|
Research on video diffusion models (text-to-video, image-to-video, video-to-video) and 3D computer vision (NeRF, Gaussian Splatting, Neural Rendering, and SLAM). |

|
Research on video understanding (object detection and segmentation, motion segmentation) and 3D computer vision (pose estimation, SLAM) for autonomous vehicles. |

|
Research on few-shot deep learning and gradient-free learning algorithms. |
|
|
|
Teaching Assistant, CMSC733 : Geometric Computer Vision
Teaching Assistant, CMSC426 : Computer Vision Teaching Assistant, CMSC434 : Human Computer Interaction |
|
|
|
Reviewer: NeurIPS, ICLR, CVPR, ECCV, RAL, ICRA, IROS, IEEE Sensor Journal
NACS Representative, UMD Graduate Student Government (2020-2021) Co-Chair, NACS Grant Review Committee (2019-2022) Staff Member, Neuromorphic Cognition Engineering Workshop (July 2018) |
|
Thanks to Jon Barron for this minimalist website template. |